Kubernetes-System-Design

Author
Abhinav Tripathy Linkedin
Introduction
When it comes to building scalable systems, kubernetes is a great tool and a quite a popular one. However, there are many fundamental concepts that one needs to think about from a system design perspective when thinking about scalable systems in the context of kubernetes. This tutorial hopes to cover some of the fundamental concepts such as databases, caching, the CAP theorem.
The CAP Theorem
CAP stands for:
CAP: Consistency, Availability, Partition Tolerance
Let us define these terms: - Consistency: any read operation that begins after a write operation completes must return that value, or the result of a later write operation - Availability: every request received by a non-failing node in the system must result in a response - Partition Tolerance: the network will be allowed to lose arbitrarily many messages sent from one node to another
The theorem:
The CAP theorem states that a distributed system cannot simultaneously be consistent, available, and partition tolerant.
An illustrated proof of the theorem.
An Example:
In order to get both availability and partition tolerance, you have to give up consistency. Consider if you have two nodes, X and Y. Now, there is a break between network communication between X and Y, so they can't sync updates. At this point you can either:
A) Allow the nodes to get out of sync (giving up consistency), or
B) Consider the cluster to be "down" (giving up availability)
The different combinations in CAP:
- CA - data is consistent between all nodes - as long as all nodes are online - and you can read/write from any node and be sure that the data is the same, but if you ever develop a partition between nodes, the data will be out of sync (and won't re-sync once the partition is resolved).
- CP - data is consistent between all nodes, and maintains partition tolerance (preventing data desync) by becoming unavailable when a node goes down.
- AP - nodes remain online even if they can't communicate with each other and will resync data once the partition is resolved, but you aren't guaranteed that all nodes will have the same data (either during or after the partition)
An image displaying the proof:

Important Note: CAP is a spectrum. What that means is that it is not a hard and fast rule that only 2 out of the 3 will work but rather it is a theorem to think about tradeoffs. Certain transactions require high availability some require high consistency. It helps a system designer to think about trade offs, optimize for these 3 important constraints.
Single Point of Failure (SPOF)
In any scalable system, we must avoid single point of failures. As the name suggests, it is a a node,(it could be any part of the system) if it fails the whole system would go down.
As an example, this image displays how a single load balancer could be an SPOF.
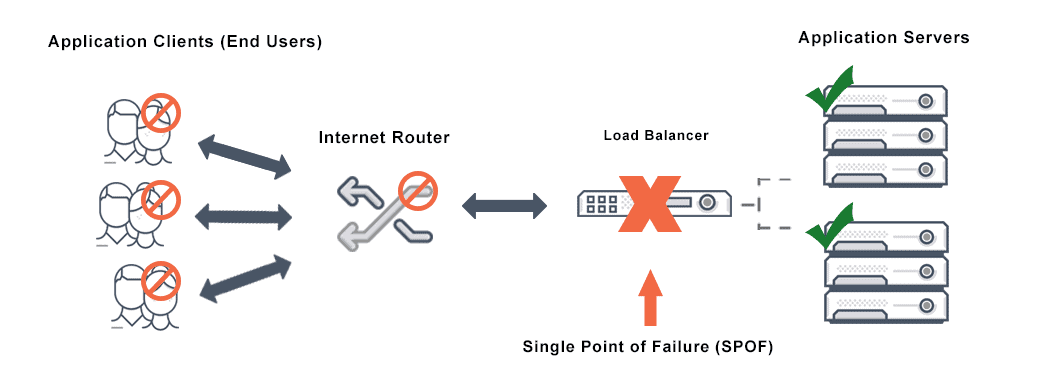
As the image suggests, having multiple load balancers is the solution.
To mitigate SPOFs we have 3 key approaches:
- More Nodes: With more nodes one can duplicate the node or service and distribute traffic among them. Another way is to use the secondary node/nodes as a backup service, though that would potentially lead to wasting resources.
- Master Slave Approach: This approach is quite useful especially in the context of databases. The main question here is what if a database goes down. This can be mitigated by having a master database off which slaves replicate. So in the case master goes down, one of the slaves can become a master. There can be additional complexity such as having multiple masters or having read only slaves/write only slaves.
- Master - Master Approach: This is like the master slave approach however in this case the two or more nodes, all get read requests and write loads are distributed among the master nodes. The advantage it is a simple automatic failover. The main disadvatange is that it is loosely consistent and it is not as simple as master-slave to configure.
- Multiple Regions: Having all resources in one region can also mean a SPOF. For instance, all your services in the cloud are in the US east region. To avoid, infrastructure going down in one area or a natural disaster happenning, having services and resources split across multiple regions is a good practice.
An Example Diagram of master slave approach:
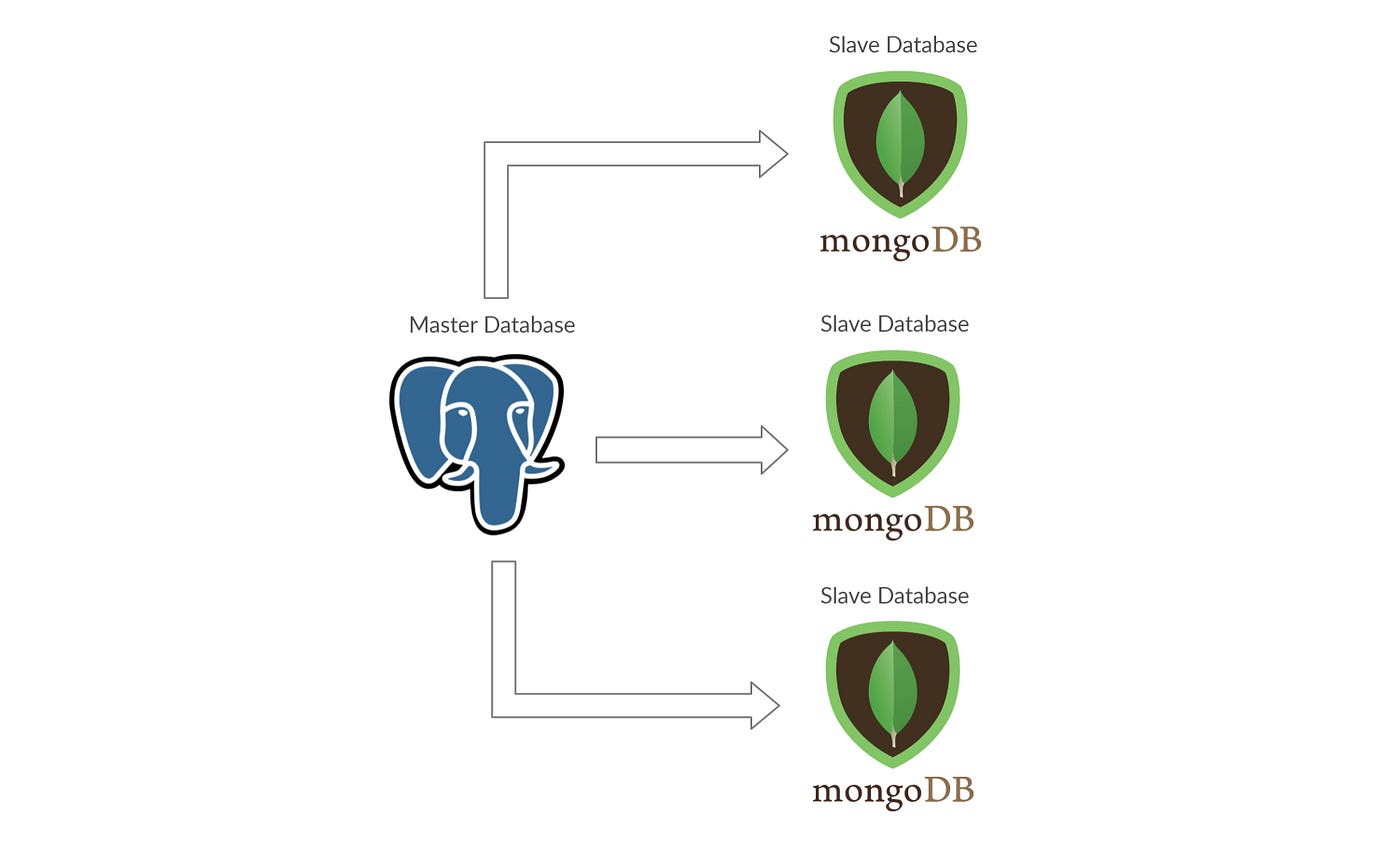
Databases
The following are some key concepts in databases.
ACID Compliance
Atomicity: Database transactions, like atoms, can be broken down into smaller parts. When it comes to your database, atomicity refers to the integrity of the entire database transaction, not just a component of it. In other words, if one part of a transaction doesn’t work like it’s supposed to, the other will fail as a result—and vice versa. For example, if you’re shopping on an e-commerce site, you must have an item in your cart in order to pay for it. What you can’t do is pay for something that’s not in your cart. (You can add something into your cart and not pay for it, but that database transaction won’t be complete, and thus not ‘atomic’, until you pay for it).
Consistency: For any database to operate as it’s intended to operate, it must follow the appropriate data validation rules. Thus, consistency means that only data which follows those rules is permitted to be written to the database. If a transaction occurs and results in data that does not follow the rules of the database, it will be ‘rolled back’ to a previous iteration of itself (or ‘state’) which complies with the rules. On the other hand, following a successful transaction, new data will be added to the database and the resulting state will be consistent with existing rules.
Isolation: It’s safe to say that at any given time on Amazon, there is far more than one transaction occurring on the platform. In fact, an incredibly huge amount of database transactions are occurring simultaneously. For a database, isolation refers to the ability to concurrently process multiple transactions in a way that one does not affect another. So, imagine you and your neighbor are both trying to buy something from the same e-commerce platform at the same time. There are 10 items for sale: your neighbor wants five and you want six. Isolation means that one of those transactions would be completed ahead of the other one. In other words, if your neighbor clicked first, they will get five items, and only five items will be remaining in stock. So you will only get to buy five items. If you clicked first, you will get the six items you want, and they will only get four. Thus, isolation ensures that eleven items aren’t sold when only ten exist.
Durability: All technology fails from time to time… the goal is to make those failures invisible to the end-user. In databases that possess durability, data is saved once a transaction is completed, even if a power outage or system failure occurs. Imagine you’re buying in-demand concert tickets on a site similar to Ticketmaster.com. Right when tickets go on sale, you’re ready to make a purchase. After being stuck in the digital waiting room for some time, you’re finally able to add those tickets to your cart. You then make the purchase and get your confirmation. However if that database lacks durability, even after your ticket purchase was confirmed, if the database suffers a failure incident your transaction would still be lost! As you might expect, this is a really bad thing to happen for an online e-commerce site, so transaction durability is a must-have.
Database Sharding
Database sharding is a popular concept when dealing with high volume data and is a very popular way to manage in No-SQL databases. Shards are autonomous and is an example to scale horizontally. Shards are basically partitions of the database based on a key. This key is what decides the shards, it could be a column value, it could be location or user ID or any other attribute that makes sense and works universally on the incoming data. Each shard can be protected by the master slave architecture for further scalability.
An example of shards:

Caching
Caching is a way to speed up retrieval of frequently or commonly accessed data. This means storing data in something like Redis that helps retrieve data very quickly. The reason this is possible is the data is stored in memory instead of a storage device like a disk(which is slower than in memory). In memory storage also means it is volatile which means it does not have ACID compliance.
Advantages of Caching
- Reduce network calls
- Reduce Recomputations
- Reduce Database load
Caching Policies
Caching policies are used to delete unnecessary cache values to make sure the cache is up to date and always fresh and relevant to the incoming requests.
- LRU Cache - Least Recently Used
- LFU Cache - Least Frequently Used Cache
- Sliding window
Updating the Cache
- Cache Aside
- Write Through
- Write Behind
- Refresh Ahead
Storing Images
Storing it as a file (in a file system)
- Storing files in a file system is often cheaper in the context of cost
- Database needs to be used to the save the file URL
- it is a static asset so can be used with CDNs - allows fast access
Storing it in a database (as a Blob)
Blob: Binary Large Object
- Storing the image as a blog in a database means there is ACID compliance which gives transaction garrantuees
- Indexes with databases can improve search
- Easy Access control with databases for images is quite useufl too
Queue Systems
Queues are used to in many scalable and distributed systems. They allow for asychronous tasks and environment to be handled which allows for better performance. It also makes a scalable system more fault tolerant as it acts as an intermediary between services. They also allow for very high throughput and scalability.
Publisher Subscriber Model
Often queues will be used through a publisher subscriber model. For Example, if we have a pizza delivery system, the client on the front-end acts as a publisher i.e. it publishes orders on to the queue. Then a service that notifies the team aobut the order is a subscriber. There can be mulitple subscribers and producers and a service can act as both.
Sample Publisher Subscriber Model:

More generall we can say that the model looks like the following:
Message Guarantees
In any system, we need to think about potential tradeoffs and guarantees. In queueing systems, one thing to talk about is processing/messaging guarantees.
- No guarantee — No explicit guarantee is provided, so consumers may process messages once, multiple times or never at all.
- At most once — This is “best effort” delivery semantics. Consumers will receive and process messages exactly once or not at all.
- At least once — Consumers will receive and process every message, but they may process the same message more than once.
- Effectively once — Also contentiously known as exactly once, this promises consumers will process every message once.
API Gateway
An API Gateway is the entry door for a client to talk to a collection of backend services. The gateway provides a single entrypoint which allows it to look for the right services to talk to in the backend the return the approporiate result.
API Gateway Architecture:

Uses for API Gateway: - Rate Limiting - Statistics & User Analytics - Handling User Authentication - Handling multiple requests in a microservices architecture
Acknowledgements
Feedback
If you have any feedback or comments or want to improve something, please open an issue on github here